Now that we know how to gather information about the system, how do we ask it to run a job for us?
SLURM needs to know two things to run a job: what we want to do and the resources we need to do it. We’ll use a shell script to specify both of these parameters.
Let’s make a new script called submit.sh. In your text editor copy and paste the following (minimal) submission script:
Save this file in its own folder with a descriptive name like myFirstSlurmJob. Place the script hello.sh from the first exercise into this folder too. Now, in order to run this job you need to be on a system that is managed by SLURM. So let’s log on to the AS-CHEM cluster.
You’ll need to be connected to the Cornell VPN to access the cluster. If you are a Cornell chemistry student and don’t have access to the cluster go see ChemIT (or your group IT representative) to set up your cluster account. If you are not a Cornell chemistry student you’ll need to follow your institution’s cluster login instructions. Depending on how your cluster is set up some of the instructions below may not work, when in doubt contact your system administrator.
Open up the command-line, type ssh <yourNetID>@cluster2020.chem.cornell.edu and you’ll see a password prompt appear. As you enter your password nothing will appear; this is normal. The terminal is recording your keystrokes as usual, but will not display them for security purposes.
NathanLui@local | ~ $ ssh nml64@cluster2020.chem.cornell.edu
Password:
Last login: Sun Dec 26 14:04:09 2021 from <IP address>
nml64@as-chm-cluster | ~ $
See how the terminal prompt has now changed from NathanLui@local to nml64@as-chm-cluster to indicate that I’m now working on the cluster. We can navigate the cluster with the same commands we learned earlier. To test our script we’ll need to use our SFTP client (FileZilla) to transfer our scripts to the cluster. If you haven’t yet, go set up FileZilla using the directions in section 1. Once you’ve done that, open FileZilla and connect to the AS-CHEM cluster. Drag your whole myFirstSlurmJob folder into the cluster pane to transfer it.
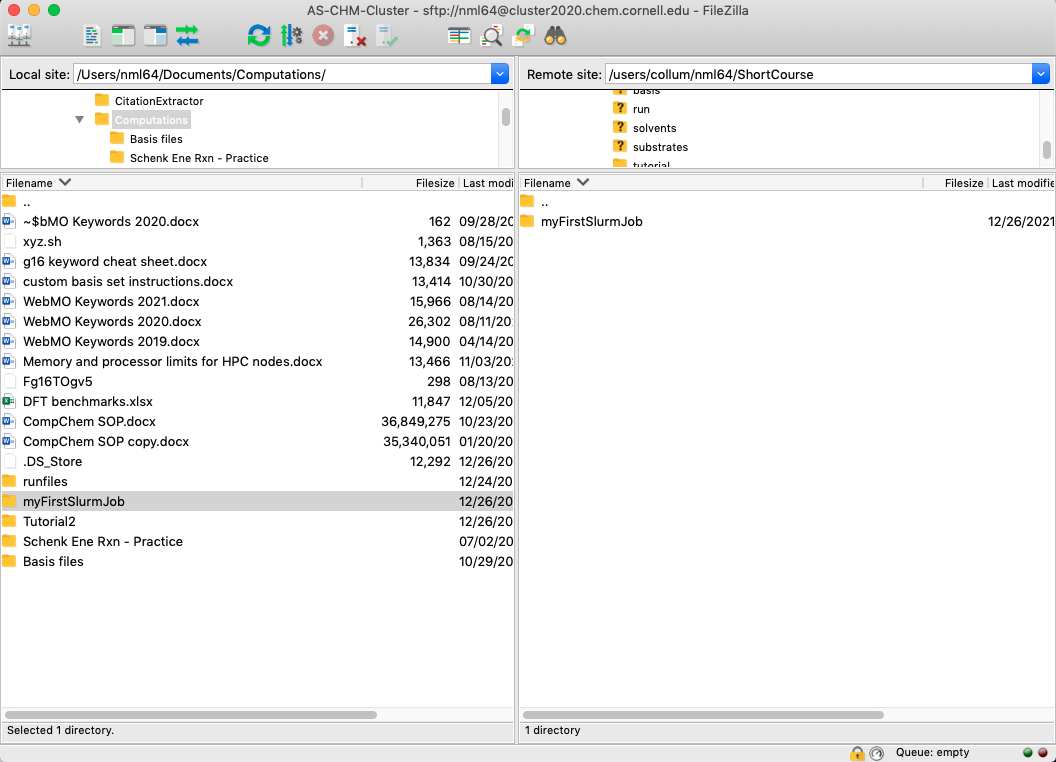
Of course, you have the option to create a new folder on the cluster directly using
mkdirand then drag the individual shell scripts into that file, but as your experience grows as will the number of files you’ll have to keep track of. It will be much more manageable if the organization of your local system mirrors that of the cluster. Transferring whole directories ensures that paths will remain the same. For more, see best practices.
Now, lets navigate into that folder and take a look:
nml64@as-chm-cluster | ~ $ cd myFirstSlurmJob/
nml64@as-chm-cluster | ~/myFirstSlurmJob $ ls -l
total 8.0K
-rwxr-xr-x 1 nml64 collum 79 Dec 26 15:59 hello.sh
-rwxr-xr-x 1 nml64 collum 338 Dec 26 15:59 submit.sh
Now we can submit our job to the SLURM workload manager:
nml64@as-chm-cluster | ~/myFirstSlurmJob $ sbatch submit.sh
Submitted batch job 8716
Checking the job queue and node status shows us the progress of our new job:
nml64@as-chm-cluster | ~/myFirstSlurmJob $ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
8716 chemq hello nml64 R 0:16 1 chem006
nml64@as-chm-cluster | ~/myFirstSlurmJob $ pestat
Hostname Partition Node Num_CPU CPUload Memsize Freemem Joblist
State Use/Tot (MB) (MB) JobId User ...
...
chem006 chemq mix 16 16 16.00 31935 29651 8716 nml64
...
But wait a second! Where is our output? We’ve tasked 16 CPUs with 28 GB of memory to tell the whole world “Hello!”, where did it all go? Let’s take a look at our directory.
nml64@as-chm-cluster | ~/myFirstSlurmJob $ ls -l
total 12K
-rwxr-xr-x 1 nml64 79 Dec 26 15:59 hello.sh
-rw-r--r-- 1 nml64 81 Dec 26 17:35 out.txt
-rwxr-xr-x 1 nml64 338 Dec 26 15:59 submit.sh
nml64@as-chm-cluster | ~/myFirstSlurmJob $ cat out.txt
Starting job
Hello world!
My favorite food is pizza.
I am years old.
Resting 30 sec
Job complete
So that’s where its all gone to! SLURM redirects all standard output from the terminal to the output file that we specified in the resource requests section.
There’s still another issue! The program doesn’t know how old we are because the environmental variable we declared in the last tutorial doesn’t get transferred with the file (i.e. we’re in a different environment). So we have to redeclare age in this environment.
This fixes our issue and if we run the job again we can see that the script works as it’s supposed to!
nml64@as-chm-cluster | ~/myFirstSlurmJob $ sbatch submit.sh
Submitted batch job 8719
nml64@as-chm-cluster | ~/myFirstSlurmJob $ ls -l
total 12K
-rwxr-xr-x 1 nml64 collum 107 Dec 26 17:46 hello.sh
-rw-r--r-- 1 nml64 collum 100 Dec 26 17:56 out.txt
-rwxr-xr-x 1 nml64 collum 352 Dec 26 17:55 submit.sh
nml64@as-chm-cluster | ~/myFirstSlurmJob $ cat out.txt
Starting job
Hello world!
My favorite food is pizza.
I am 26 years old.
Resting 30 sec
Job complete
🍾👏🍾 Congrats!!! You just ran your first SLURM job 🍾👏🍾
SLURM will overwrite data files with the same name
One important thing to note is that we ran this job multiple times in the same directory. So SLURM wrote over out.txt the second time we ran the job. There is no way to get back our first out.txt (trivially, you could scroll up in the terminal history looking for our previous cat out.txt call, but this isn’t really a generalizable solution). This could be problematic since we might not remember how we got to the previous out.txt and how to recreate its results. In general, a single folder should represent a single program call so that unintentional overwrites cannot happen. In other words:
Every new job should begin in its own new folder.
In the next section, we’ll talk about the final part of our recipe: the Gaussian input file.
SLURM Basics |
Gaussian Input Files |